BranchCache, eine Technologie die mit dem Windows Server 2008 R2 und Windows 7 eingeführt wurde, ermöglicht es, den Datenverkehr auf WAN-Strecken und die damit einhergehende Wartezeit bei der Übertragung zu reduzieren. Es geht darum, den lesenden Zugriff von einem Unternehmens-Standort (hier als “Filiale” bezeichnet) auf Daten in einem anderen Standort (hier als “Firmensitz” bezeichnet) zwischen zu speichern (“caching”).
Grundsätzlich stehen zwei verschiedene Modi zur Verfügung:
- Hosted Cache (“Gehosteter Cache”)
- Distributed Cache (“Verteilter Cache”)
Beim Hosted Cache übernimmt ein Server in der Filiale die Aufgabe des Caches. Er speichert die Daten entsprechend zwischen. Beim Distributed Cache wird auf einen dedizierten Server verzichtet – die Clients der Filiale übernehmen das Caching. Vorteil des Distributed Cachings ist also der Verzicht auf zusätzliche Hardware und den damit verbundenen Verwaltungsaufwand. Allerdings entsteht der Nachteil, dass das Endgerät, welches die Daten in seinem Cache hält, zum benötigten Zeitpunkt nicht online ist und somit der Cache nicht genutzt werden kann.
Es existieren mittlerweile zwei verschiedene Versionen:
- V1 steht bereits ab Windows Server 2008 R2 und Windows 7 zur Verfügung
- V2 steht erst ab Windows Server 2012 und Windows 8 zur Verfügung
Der Ablauf beim Distributed Cache ist (etwas vereinfacht) der folgende:
- Client1 in der Filiale soll ein File auf einem Dateiserver am Firmensitz öffnen; durch eine GPO ist er für BranchCache und den Modus “Distributed Cache” konfiguriert. Beim Dateiserver fragt er nicht die Datei selber sondern deren Hash (eine Art Fingerabdruck, die das File in seiner aktuellen Version identifiziert) an.
- Der Dateiserver überträgt den Hash zum Client1 (Der Hash wurde vom Dateiserver generiert, dieser ist ebenfalls durch eine GPO entsprechend konfiguriert)
- Client1 fragt per Broadcast in seinem Subnetz an, ob andere Clients das File in ihrem Cache haben, welches durch den Hash identifiziert wird; im Beispiel gehen wir nun davon aus, dass keiner der anderen Clients dieses File bisher geöffnet hat
- Client1 fragt nun noch einmal beim Dateiserver an; dieses Mal jedoch direkt nach der Datei statt nach deren Hash
- Die Datei wird zum Client1 übertragen und dort geöffnet
- Wenn nun auch Client2 in der Filiale diese Datei öffnen will, dann beginnt der Prozess wieder “von neuem”: Client2 fragt beim Dateiserver den Hash für das File an
- Der Dateiserver überträgt den Hash an Client2
- Client2 fragt per Broadcast in seinem Subnetz nach dem Hash
- Client1 meldet sich, da dieser das File in seinem Cache hat (Voraussetzung ist, dass sich das File zwischenzeitlich auf dem Dateiserver nicht geändert hat, denn dann hätte es einen anderen Hash!); Die Datei wird nun aus dem Cache von Client1 zum Client2 übertragen; dieser kann das File nun öffnen (und er hält es fortan auch in seinem Cache vor!)
Dabei haben also folgende Übertragungen stattgefunden:
- 2x Abfrage des Hashes über WAN
- 1x Übertragung des Files über WAN
- 1x Übertragung des Files über LAN
Eingespart wurde also die zweite Übertragung des Files über WAN; stattdessen kommt die Übertragung der Hashes hinzu, die aber im Verhältnis deutlich kleiner sind
BranchCache ist also insbesondere sinnvoll bei:
- Unternehmen mit verschiedenen Standorten
- Häufigen lesenden Zugriffen auf sich selten ändernde Dateien über das gesamte Unternehmensnetzwerk
Die Edition des Server-Betriebssystems spielt bei einem Server 2012 R2 keine Rolle, bei den Clients muss unter Windows 8.1 die Enterprise-Edition eingesetzt werden. (Unter Server 2008 R2 muss der Caching-Server mindestens die Enterprise-Edition verwenden, für den Dateiserver spielt die Edition keine Rolle; Windows 7 Clients müssen mindestens die Enterprise-Edition verwenden.)
Im Folgenden möchte ich den Aufbau einer einfachen BranchCache-Umgebung darstellen. Dabei gibt es einen Server, SRV1, der neben der Aufgabe des Domänen-Controllers auch gleichzeitig die Aufgabe des Dateiserver übernimmt. Die beiden Clients WIN8-1 und WIN8-2 werden dann den Zugriff auf eine Datei des Dateiservers durchführen.
Auf SRV1 wird über den Servermanager / “Verwalten” / “Rollen und Features hinzufügen” ein Rollendienst hinzugefügt:

Unterhalb der Rolle “Datei-/Speicherdienste” findet sich “BranchCache für Netzwerkdateien”:

Nach der Installation dieses Rollendienstes kann nun an jeder Freigabe, bei der dies gewünscht ist, BranchCache aktiviert werden. Dies geschieht in den Eigenschaften der “Erweiterten Freigabe” über den Button “Zwischenspeichern”:


Als nächstes müssen nun zwei Gruppenrichtlinien konfiguriert werden:
- CPR_BranchCache_Content ist für den Fileserver gedacht und wird sinnvollerweise über die Sicherheitsfilter nur auf diese angewendet
- CPR_BranchCache_Clients ist für die Clients gedacht und kann z.B. per WMI-Filter dynamisch auf diese wirken

Innerhalb der Content-Policy wird zum einen die Hash-Veröffentlichung aktiviert und zum anderen die Version festgelegt. Man kann hier zwischen “Nur V1”, “V1 und V2” oder “Nur V2” wählen:

Der relevante Pfad innerhalb der GPO lautet “Computerkonfiguration” / “Richtlinien” / “Administrative Vorlagen” / “Netzwerk” / “LanMan-Server”


Innerhalb der Client-Policy sind etwas mehr Einstellungen vorzunehmen:

Hier muss BranchCache aktiviert werden, der Modus “Verteilter Cache” festgelegt werden und optional können die maximale Speicherbelegung, das maximale Alter und weitere Dinge konfiguriert werden. Aus Demo-Zwecken werde ich außerdem in der Einstellung “BranchCache für Netzwerkdateien konfigurieren” die minimale Latenz von 80ms auf 0ms herabsetzen und somit das Nutzen des Caches auch in einem schnellen Netzwerk erzwingen:
 |
 |
 |
 |
 |
Sinnvollerweise wird nun auf dem Server und den Clients ein gpupdate durchgeführt, um nicht erst auf das Verarbeiten der GPOs warten zu müssen:

Nun kann man auf den Clients noch einmal die Branchcache-Konfiguration überprüfen. Dies geschieht mit Hilfe des Aufrufes
netsh branchcache show status all
Sollte dann in etwa so aussehen:

Nun kann mittels Leistungsüberwachung getestet werden, ob die Konfiguration funktioniert. Dazu sind die entsprechenden Indikatoren hinzuzufügen:

Sinnvollerweise schaltet man nun die Leistungsüberwachung auf “Bericht” um (drittes Symbol in der Leiste oben von links gezählt).
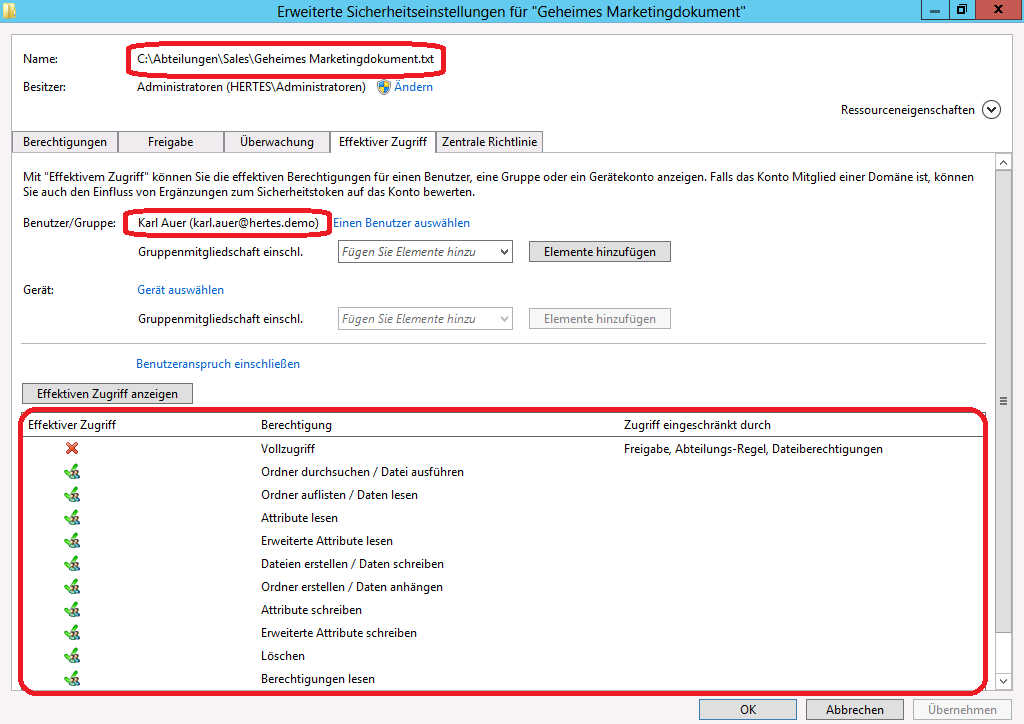
Der Benutzer “Franz Iskaner” öffnet nun von WIN8-1 aus ein Dokument auf dem Dateiserver:

Eine Eigenart des integrierten PDF-Readers auf WIndows 8 ist, dass dieser das Dokument nur in Teilen öffnet und beim Lesen dann entsprechend die Inhalte nachlädt. Daher wurde nun also nicht das gesamte Dokument mit ca. 13MB sondern nur ein Teil davon vom Server abgerufen (ich habe die ersten hundert Seiten von ca. 2000 durchgeblättert):

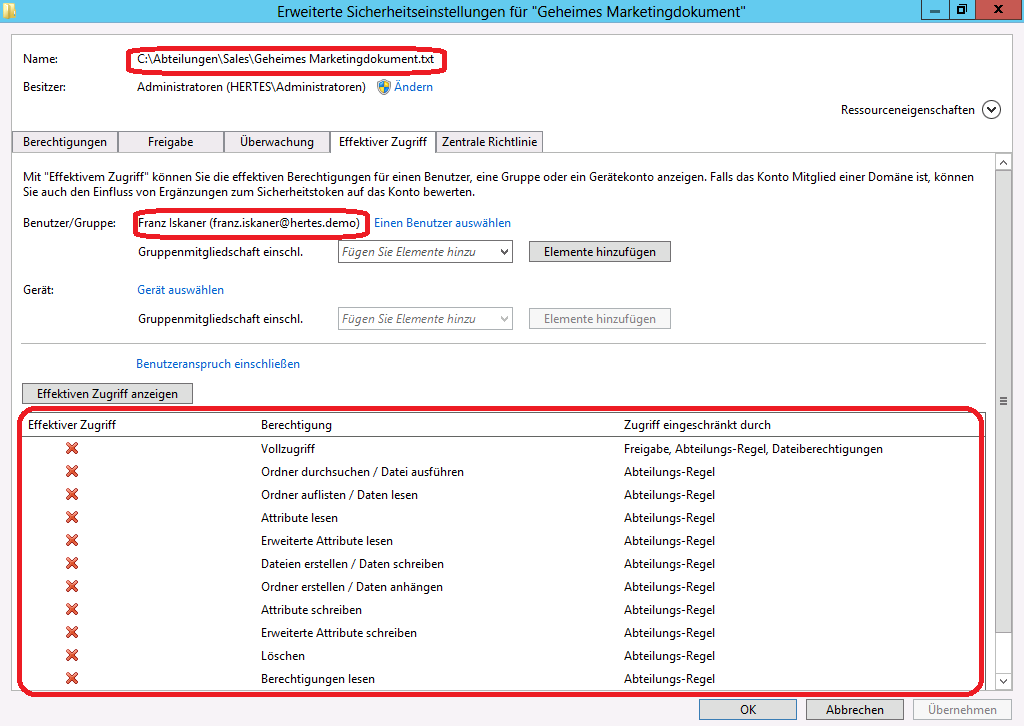
Auf WIN8-2 öffnet nun “Karl Auer” das selbe Dokument, die Leistungsüberwachung ist geöffnet und zeigt nun folgende Werte auf WIN8-2:

(WIN8-1 hatte zwischenzeitlich weitere Teile des Dokumentes abgerufen, weshalb WIN8-2 etwas mehr vom Cache abrufen konnte als WIN8-1 im oberen Screenshot vom Server abgerufen hatte)
Ein Teil des Dokumentes kommt hier (das aber insbesondere wegen des PDF-Readers) immer noch vom Server – nämlich der Teil, der nicht im Cache auf WIN8-1 liegt, weil er dort bisher nicht geöffnet wurde.
Die Funktionsfähigkeit der BranchCache-Konfiguration ist damit aber gezeigt.
An dieser Stelle sei nochmal darauf hingewiesen, das BranchCache nur LESEND funktioniert – beim Schreiben wird direkt auf den Server geschrieben und nicht in den Cache!
Weitere Informationen zum Thema Branchcache finden sich im Microsoft Technet:
http://technet.microsoft.com/de-de/library/hh831696.aspx
Schreibe einen Kommentar...